我们在 tools/ 文件夹路径下提供了许多有用的工具。
日志分析¶
给定一个训练的日志文件,您可以绘制出 loss/mAP 曲线。首先需要运行 pip install seaborn 安装依赖包。
python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}] [--mode ${MODE}] [--interval ${INTERVAL}]
注意: 如果您想绘制的指标是在验证阶段计算得到的,您需要添加一个标志 --mode eval ,如果您每经过一个 ${INTERVAL} 的间隔进行评估,您需要增加一个参数 --interval ${INTERVAL}。
示例:
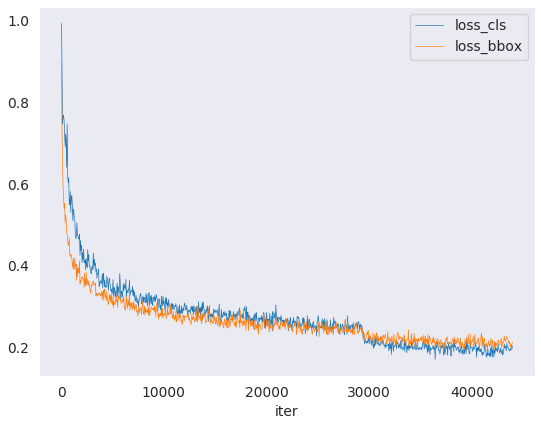
绘制出某次运行的分类 loss。
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
绘制出某次运行的分类和回归 loss,并且保存图片为 pdf 格式。
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
在同一张图片中比较两次运行的 bbox mAP。
# 根据 Car_3D_moderate_strict 在 KITTI 上评估 PartA2 和 second。 python tools/analysis_tools/analyze_logs.py plot_curve tools/logs/PartA2.log.json tools/logs/second.log.json --keys KITTI/Car_3D_moderate_strict --legend PartA2 second --mode eval --interval 1 # 根据 Car_3D_moderate_strict 在 KITTI 上分别对车和 3 类评估 PointPillars。 python tools/analysis_tools/analyze_logs.py plot_curve tools/logs/pp-3class.log.json tools/logs/pp.log.json --keys KITTI/Car_3D_moderate_strict --legend pp-3class pp --mode eval --interval 2
您也能计算平均训练速度。
python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
预期输出应该如下所示。
-----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
slowest epoch 11, average time is 1.2024
fastest epoch 1, average time is 1.1909
time std over epochs is 0.0028
average iter time: 1.1959 s/iter
模型部署¶
注意:此工具仍然处于试验阶段,目前只有 SECOND 支持用 TorchServe 部署,我们将会在未来支持更多的模型。
为了使用 TorchServe 部署 MMDetection3D 模型,您可以遵循以下步骤:
1. 将模型从 MMDetection3D 转换到 TorchServe¶
python tools/deployment/mmdet3d2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
--output-folder ${MODEL_STORE} \
--model-name ${MODEL_NAME}
Note: ${MODEL_STORE} 需要为文件夹的绝对路径。
2. 构建 mmdet3d-serve 镜像¶
docker build -t mmdet3d-serve:latest docker/serve/
3. 运行 mmdet3d-serve¶
查看官网文档来 使用 docker 运行 TorchServe。
为了在 GPU 上运行,您需要安装 nvidia-docker。您可以忽略 --gpus 参数,从而在 CPU 上运行。
例子:
docker run --rm \
--cpus 8 \
--gpus device=0 \
-p8080:8080 -p8081:8081 -p8082:8082 \
--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
mmdet3d-serve:latest
阅读文档 关于 Inference (8080), Management (8081) and Metrics (8082) 接口。
4. 测试部署¶
您可以使用 test_torchserver.py 进行部署, 同时比较 torchserver 和 pytorch 的结果。
python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}]
例子:
python tools/deployment/test_torchserver.py demo/data/kitti/kitti_000008.bin configs/second/hv_second_secfpn_6x8_80e_kitti-3d-car.py checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-car_20200620_230238-393f000c.pth second
模型复杂度¶
您可以使用 MMDetection 中的 tools/analysis_tools/get_flops.py 这个脚本文件,基于 flops-counter.pytorch 计算一个给定模型的计算量 (FLOPS) 和参数量 (params)。
python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
您将会得到如下的结果:
==============================
Input shape: (4000, 4)
Flops: 5.78 GFLOPs
Params: 953.83 k
==============================
注意:此工具仍然处于试验阶段,我们不能保证数值是绝对正确的。您可以将结果用于简单的比较,但在写技术文档报告或者论文之前您需要再次确认一下。
计算量 (FLOPs) 和输入形状有关,但是参数量 (params) 则和输入形状无关。默认的输入形状为 (1, 40000, 4)。
一些运算操作不计入计算量 (FLOPs),比如说像GN和定制的运算操作,详细细节请参考
mmcv.cnn.get_model_complexity_info()。我们现在仅仅支持单模态输入(点云或者图片)的单阶段模型的计算量 (FLOPs) 计算,我们将会在未来支持两阶段和多模态模型的计算。
模型转换¶
RegNet 模型转换到 MMDetection¶
tools/model_converters/regnet2mmdet.py 将 pycls 预训练 RegNet 模型中的键转换为 MMDetection 风格。
python tools/model_converters/regnet2mmdet.py ${SRC} ${DST} [-h]
Detectron ResNet 转换到 Pytorch¶
MMDetection 中的 tools/detectron2pytorch.py 能够把原始的 detectron 中预训练的 ResNet 模型的键转换为 PyTorch 风格。
python tools/detectron2pytorch.py ${SRC} ${DST} ${DEPTH} [-h]
准备要发布的模型¶
tools/model_converters/publish_model.py 帮助用户准备他们用于发布的模型。
在您上传一个模型到云服务器 (AWS) 之前,您需要做以下几步:
将模型权重转换为 CPU 张量
删除记录优化器状态 (optimizer states) 的相关信息
计算检查点 (checkpoint) 文件的哈希编码 (hash id) 并且把哈希编码加到文件名里
python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
例如,
python tools/model_converters/publish_model.py work_dirs/faster_rcnn/latest.pth faster_rcnn_r50_fpn_1x_20190801.pth
最终的输出文件名将会是 faster_rcnn_r50_fpn_1x_20190801-{hash id}.pth。
数据集转换¶
tools/dataset_converters/ 包含转换数据集为其他格式的一些工具。其中大多数转换数据集为基于 pickle 的信息文件,比如 KITTI,nuscense 和 lyft。Waymo 转换器被用来重新组织 waymo 原始数据为 KITTI 风格。用户能够参考它们了解我们转换数据格式的方法。将它们修改为 nuImages 转换器等脚本也很方便。
为了转换 nuImages 数据集为 COCO 格式,请使用下面的指令:
python -u tools/dataset_converters/nuimage_converter.py --data-root ${DATA_ROOT} --version ${VERSIONS} \
--out-dir ${OUT_DIR} --nproc ${NUM_WORKERS} --extra-tag ${TAG}
--data-root: 数据集的根目录,默认为./data/nuimages。--version: 数据集的版本,默认为v1.0-mini。要获取完整数据集,请使用--version v1.0-train v1.0-val v1.0-mini。--out-dir: 注释和语义掩码的输出目录,默认为./data/nuimages/annotations/。--nproc: 数据准备的进程数,默认为4。由于图片是并行处理的,更大的进程数目能够减少准备时间。--extra-tag: 注释的额外标签,默认为nuimages。这可用于将不同时间处理的不同注释分开以供研究。
更多的数据准备细节参考 doc,nuImages 数据集的细节参考 README。